Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
单位: 上海交通大学、商汤、上海AI Lab
论文地址:https://arxiv.org/abs/2112.03649
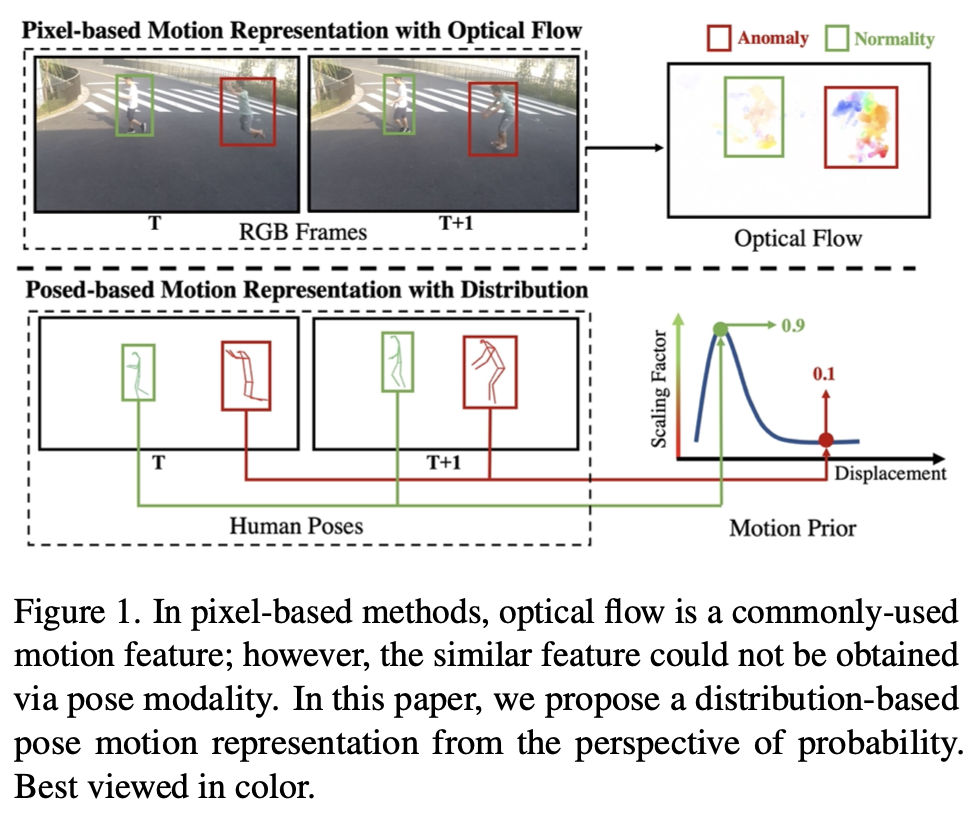
基于像素的方法可以直接利用显式运动特征比如光流,但基于姿态的方法缺乏运动表示。本文提出了一种新的Motion Embedder (ME),从概率角度提供姿态的运动表示。此外,还采用了一种新的特定任务的Spatial-Temporal Transformer(STT)来进行自监督的姿态序列重构。然后将这两个模块集成到一个统一的姿态规则学习框架中,称为Motion Prior Regularity Learner (MoPRL)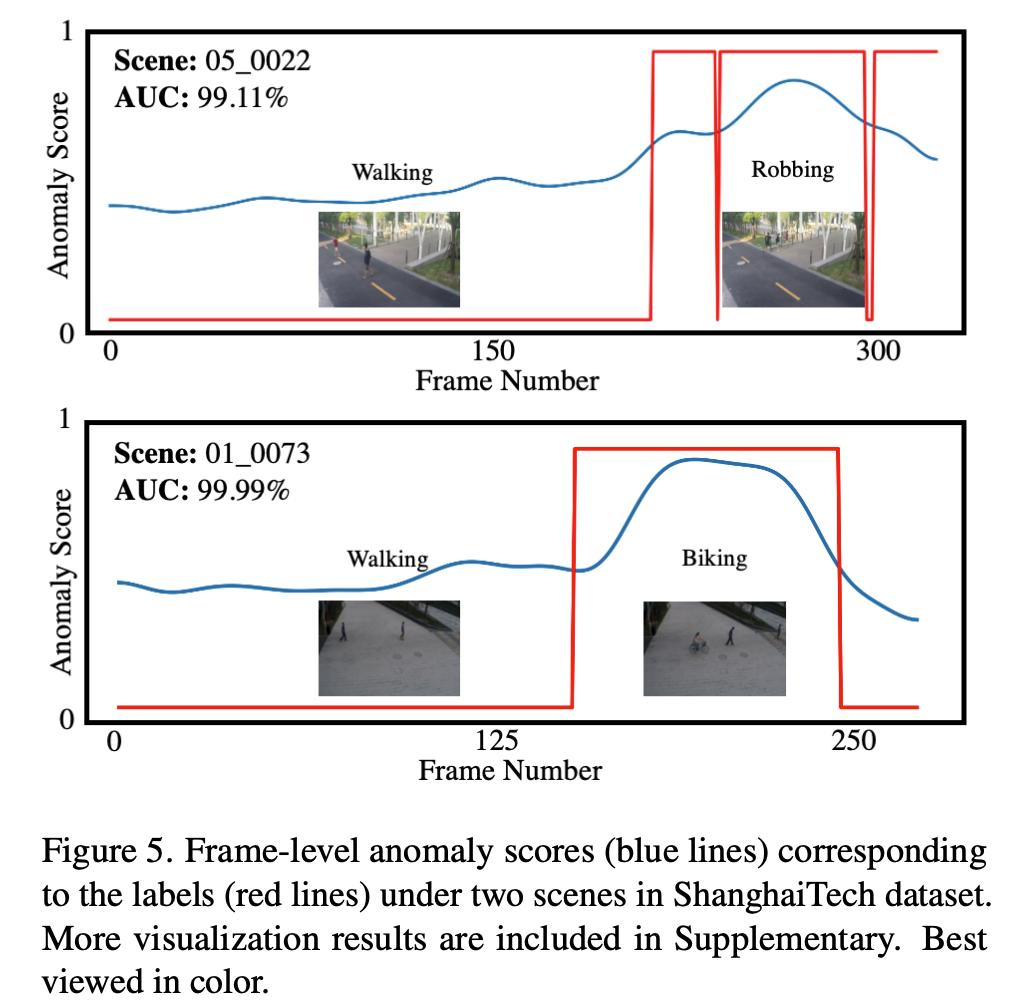
解决的问题
有效的运动表示是视频异常检测中学习正常模式的关键。在之前的基于姿态的方法中,研究人员通常利用单人关节编码视觉特征,缺乏直观的运动表示。在这种情况下模型无法同时学习运动和正常模式,从而影响其性能。
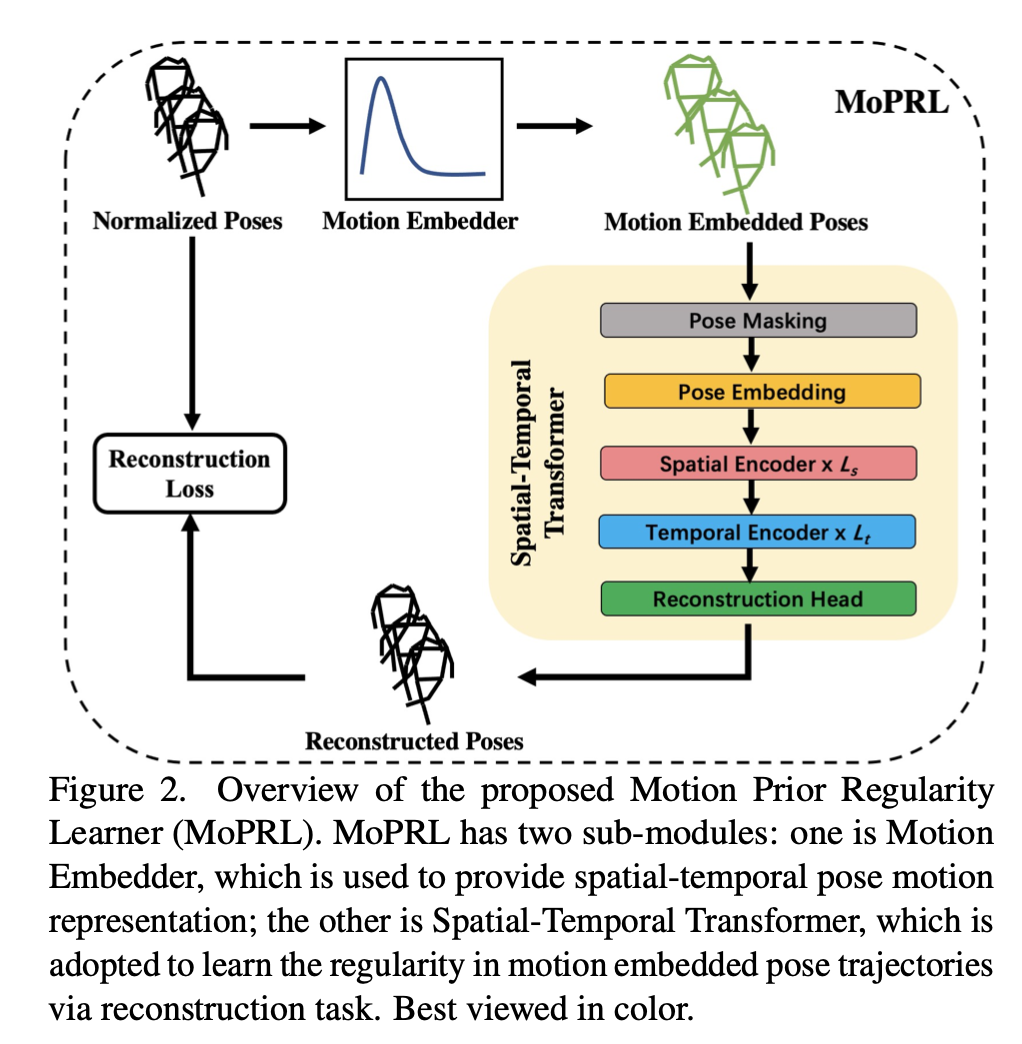
模型结构
MoPRL由两个子模块组成Motion Embedder (ME)和Temporal Transformer(STT)。首先利用一个姿态估计来获取姿态轨迹,MoPRL根据统计将基于姿势的运动表示建模为概率分布,并通过ME融合空间和时间表示。然后STT被用于通过自监督重构任务学习时空规律。通过这种方法,模型学习正态样本的分布,最后可以根据帧异常分数检测异常
Motion Embedder
ME旨在从概率角度提取输入姿态的时空表示。受基于像素的方法中常用的帧梯度的启发,提出基于相邻帧之间姿态中心点之间的位移对姿态运动进行建模。然而,直接应用位移作为运动表示过于简化。假设异常很少发生,进一步提出将这种运动表示转化到概率域,为其规律性学习提供了有效的姿态运动表示。
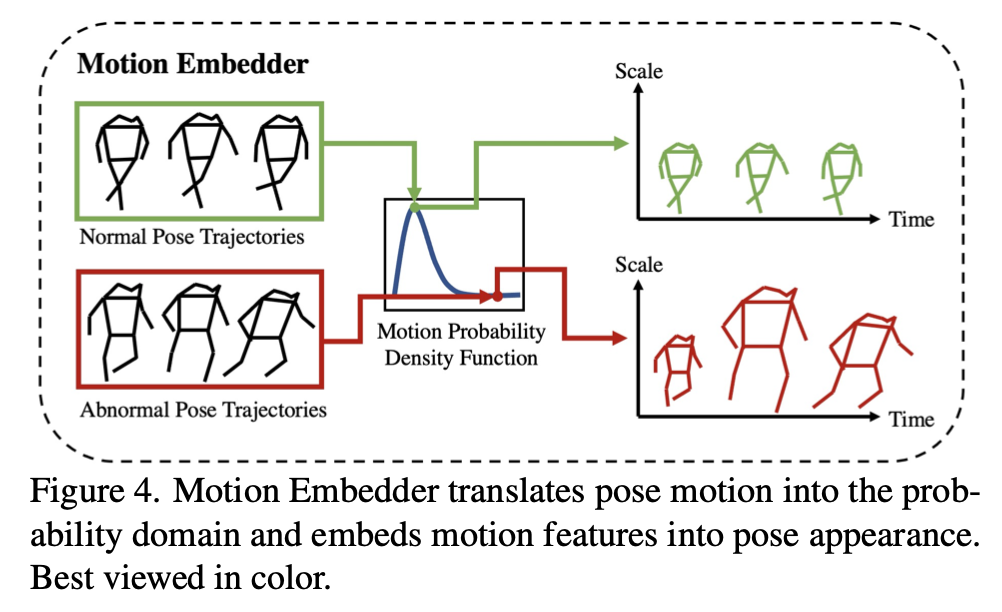
首先通过计算训练集中正常模式来获得位移的统计信息。直观地说,我们使用一个预定义的分布函数来拟合这个离散化的数据分布,通过它我们可以得到一个连续的分布。称这种连续分布为Motion Prior。将概率作为比例因子,如图所示,如果出现频率较低,可以获得更大尺寸的姿态
Spatial-Temporal Transformer
与以前基于RNN或CNN的框架不同,transformer采用了自监督和序列输入结构,适合姿态的规则性学习。
然而,正常的Transformer模型计算复杂度随着关节数和姿态数增加呈指数增长。本文将注意力机制划分为空间和时间两部分以减少计算复杂度。称这种变型为Spatial-Temporal Transformer (STT)。
实验
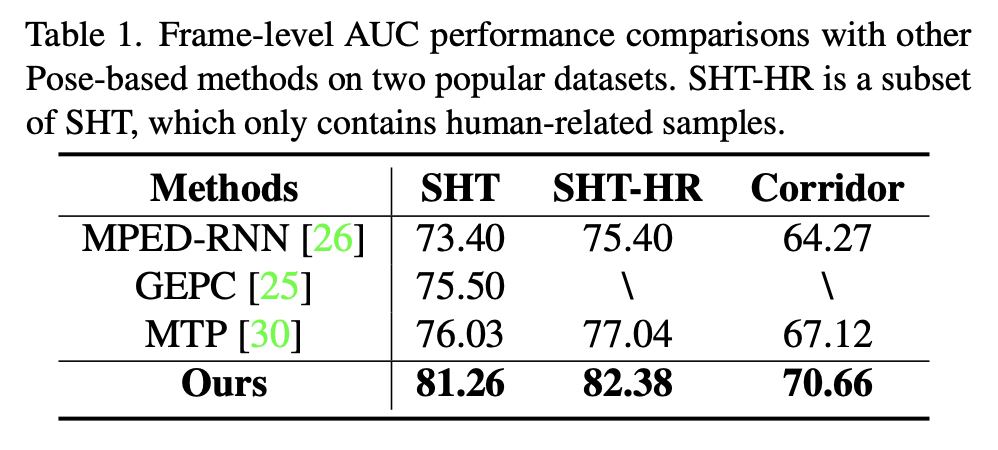
本文还观察到,序列建模使用RNN在应用ME时实际上会导致性能下降(-3.84%)。说明基于RNN的模型实际上限制了此类运动表示的性能增益。与STT相比,RNN模型重建姿态时,即使是正常样本,也会出现较大偏差。而这样的偏差实际上掩盖了由运动先验带来的正常和异常之间的区别。总之,运动表示和有效的序列建模对于基于姿态的视频异常检测来说都是重要且不可或缺的。